Build AI apps and agents
that work.
Build with confidence, knowing your AI is accurate and grounded in fast, relevant data.
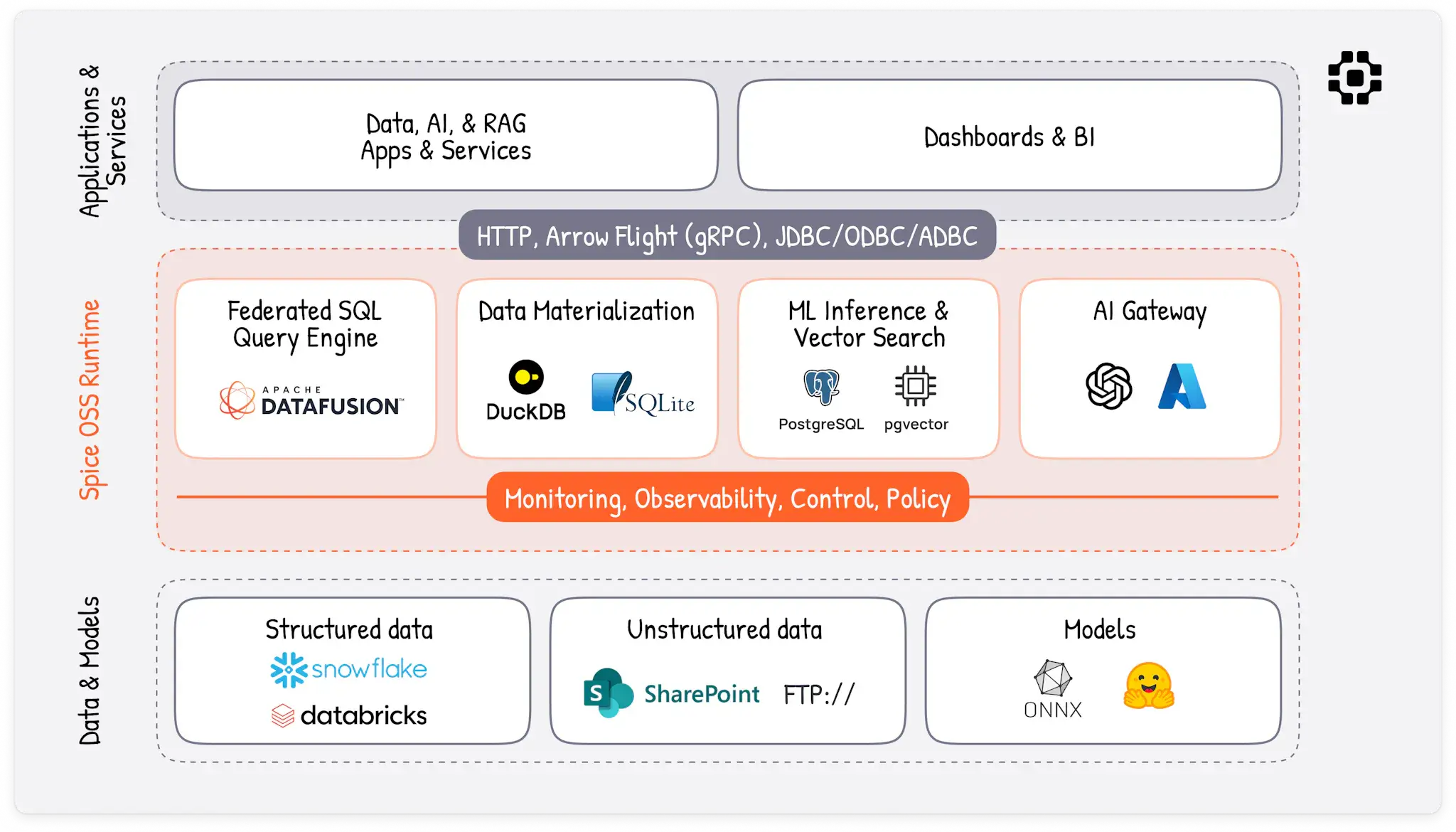
Spice is an open-source SQL query and AI-inference engine, built in Rust, for developers.
Powered by


Spice simplifies building AI apps and agents that work, by making it fast and easy to ground AI in data.
Federated Data Access
SQL API to query structured and unstructed data across databases, data warehouses, and data lakes.
DocsAI Compute Engine
OpenAI-compatible API for local and hosted inference, search, memory, evals, and observability.
DocsData Acceleration
Materialize data and content in DuckDB, SQLite, and PostgreSQL; in-memory or on disk. Results caching included.
DocsSelf-Hostable and Open-Source
Self-hostable binary or Docker image, platform-agnostic, and Apache 2.0 licensed. Built on industry standard technologies including Apache DataFusion and Apache Arrow.
DocsBefore and With Spice
See how Spice has been deployed in production architectures.
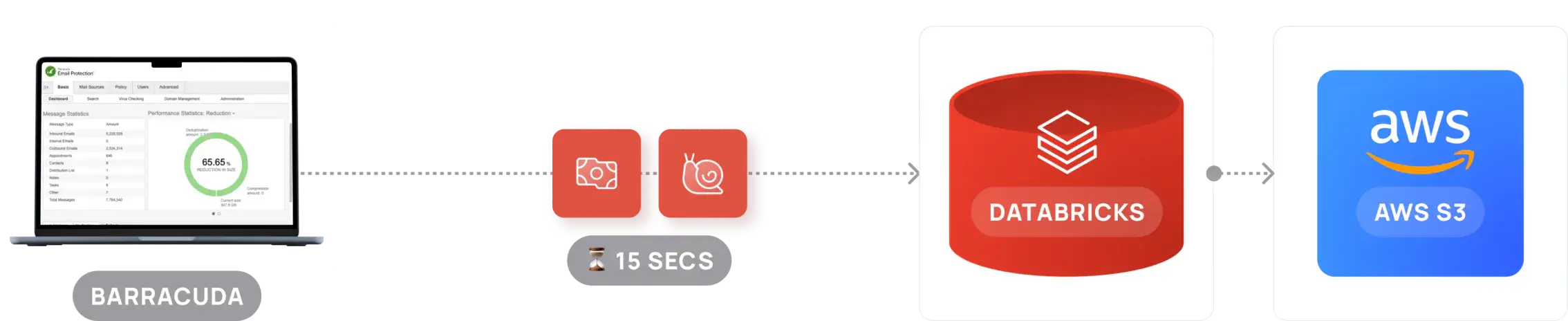
Slow 15 sec queries across 100B+ rows.
Poor user experience with slow page loads.
Unnecessary Databricks workspace expense.
Use-Cases
Spice powers data apps and AI agents with federated SQL, vector search, LLM memory, real-time data acceleration, observability, and integration across modern and legacy systems.
Agentic AI Applications
Build data-grounded AI apps and agents with local or hosted models, LLM memory, evals, and observability.
Retrieval-Augmented Generation (RAG)
Ensure AI is grounded in data with high-performance search and text-to-SQL, across a semantic knowledge layer.
Database CDN
Co-locate working sets of data in Arrow, SQLite, and DuckDB with applications for fast, sub-second query.
Distributed Data Mesh
Use SQL to query across databases, data warehouses, and data lakes with advanced federation.
Agentic AI Applications
Build data-grounded AI apps and agents with local or hosted models, LLM memory, evals, and observability.
Retrieval-Augmented Generation (RAG)
Ensure AI is grounded in data with high-performance search and text-to-SQL, across a semantic knowledge layer.
Database CDN
Co-locate working sets of data in Arrow, SQLite, and DuckDB with applications for fast, sub-second query.
Distributed Data Mesh
Use SQL to query across databases, data warehouses, and data lakes with advanced federation.
Secure, highly-available access to data. Ridiculously easy setup. Super fast data-grounded AI.
“We have been looking for a way to accelerate queries from our Databricks workspaces. Spice was the perfect solution, as it was super simple to setup and it was easy to define and query accelerated datasets without a lot of overhead.”
Andy Blyler
Chief Data Officer at Barracuda

