In February, we announced Spice.ai OSS v0.6 with its data processing and transport completely rebuilt upon Apache Flight. This enables Spice.ai OSS to scale to datasets 10-100 times larger and brings Spice.ai into the Apache Arrow ecosystem paving the way for integrations with many popular projects, like Apache Parquet, pandas and big data systems like Hive, Drill, Spark, Snowflake, BigQuery, and many more.
In Spice.ai OSS v0.6.1 we announced a new big data system integration… our own, Spice.xyz!
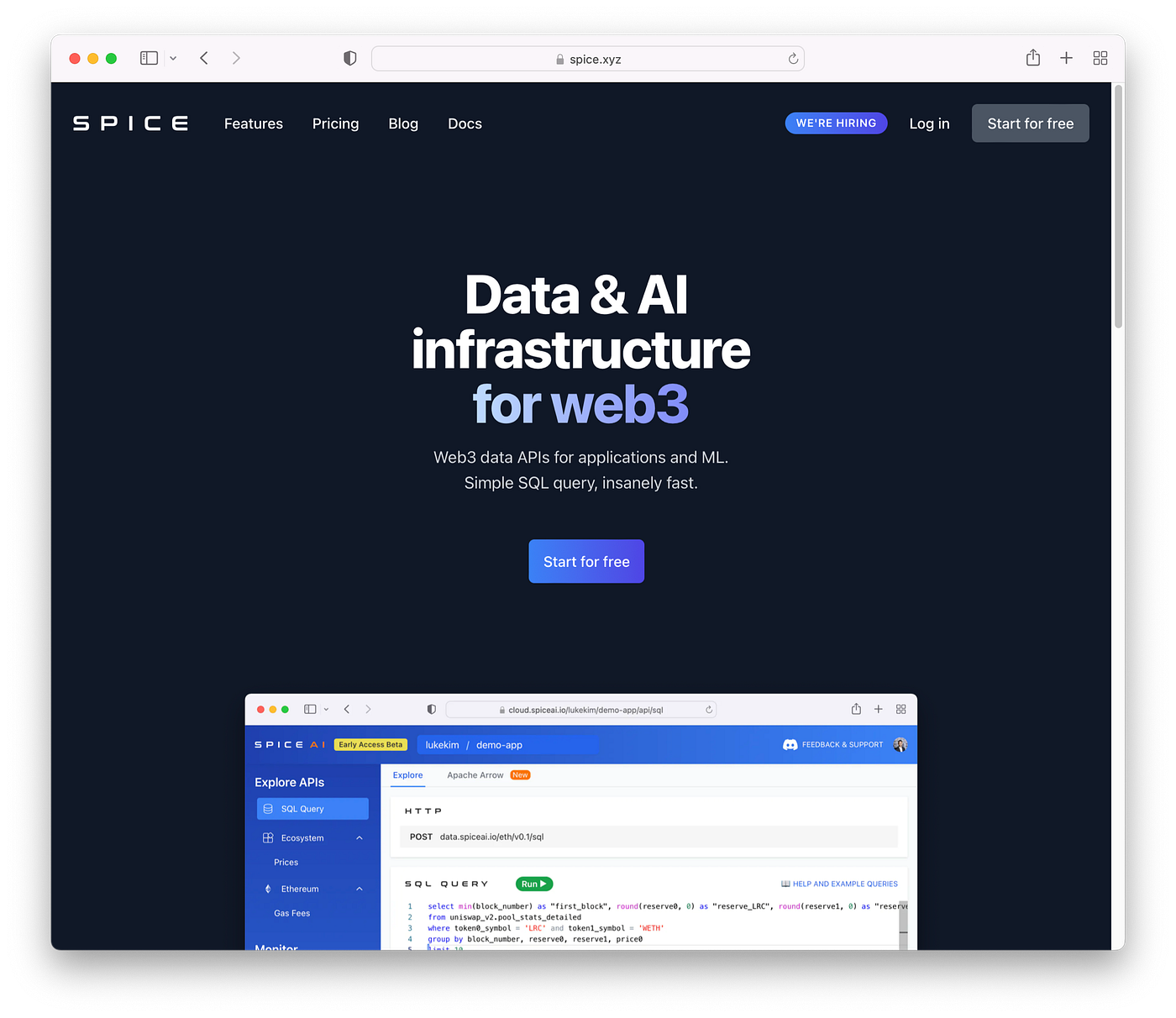
 Figure 1. Spice.xyz - Data and AI infrastructure for web3
Figure 1. Spice.xyz - Data and AI infrastructure for web3
Spice.xyz is data and AI infrastructure for web3.
It’s web3 data made easy. Insanely fast and purpose designed for applications and ML.
Spice.xyz delivers data in Apache Arrow format, over high-performance Apache Arrow Flight APIs to your application, notebook, ML pipeline, and of course, to the Spice.ai runtime.
With Spice.ai OSS v0.6.1, a new Apache Arrow Flight data connector was made available, creating a high-performance bulk-data transport directly into the Spice.ai ML engine. Coupled with Spice.xyz, developers can quickly and easily build web3 data-driven applications that learn and adapt using Spice.ai.
To read the announcement post for Spice.xyz, visit blog.spice.xyz.
Apache Arrow is a specification for an in-memory columnar data format that’s very efficient for analytics operations. Arrow’s zero-copy read semantics coupled with the Flight client-server framework mean extremely fast and efficient data transport and access without serialization overhead. This enables high-performance bulk-data scenarios, critical for data-driven applications and ML. These properties enable an open-architecture based on Apache Arrow, Flight, and Parquet.
Paul Dix, CTO of InfluxData wrote a fantastic post on the Arrow ecosystem and why the future core of InfluxDB is built with Arrow. Sam Crowder also wrote A (Recent) History of Batch Data showing how Arrow is a cornerstone of modern data architecture.
Joining projects like InfluxDB, the core of both Spice.ai OSS and Spice.xyz are built with a foundation of Arrow and Flight. This means they benefit from the same high-performance data operations, they work great with each other and other projects in the ecosystem.
Betting on Arrow in Spice.ai enables exciting new applications because AI needs AI-ready data.
Previously it was difficult to efficiently get bulk data from a provider like Spice.xyz to the Spice.ai engine, but now it's just a matter of configuring the connection through a few lines of YAML.
Imagine creating an application to trade NFTs. With Spice.xyz, developers can query Ethereum for data relating to NFT trading activity. That data is then delivered with the high-performance Arrow format to the Spice.ai runtime. The application’s Spicepod could learn how to value NFTs based upon it’s trading history and the communities it’s owners have been engaged in. And this could be all done in real-time, something not feasible before.
In addition, using the Arrow Flight connector, other exciting applications are enabled across a ton of domains, like IoT, financial applications, security monitoring, and many more.
To get somewhere you need a goal or destination, a vehicle to get there, and fuel for that vehicle.
When it comes to intelligent, AI-driven applications, Spice.xyz now provides the Spice.ai vehicle with a massive pipeline of web3 data fuel.
The next step is to make it easier for developers to define the destination for the vehicle. Upcoming on the Spice.ai OSS roadmap is the ability for developers to define goals for how the decision-engine should learn. Like learning to maximize measurement “A” or optimizing to a target of “B”.
For example, in web3, this might be to build a client that can learn and adapt to optimize Ethereum Gas Fee prices for token swaps. The goal would be to minimize the gas fee, a problem we experienced first-hand when we built defly.ai. Today you have to encode that goal into your reward function, but our plan is to help do that for you, and all you have to do is tell us the end goal.
Goal-oriented learning applies to many domains, whether it be minimizing fees in crypto or maximizing engagement on a social platform. And personally, we’re excited about the eventual ability to apply Spice.ai and just say “minimize my taxes” :-)
Even for advanced developers, building intelligent apps that leverage AI is still way too hard. Our mission is to make this as easy as creating a modern web page. If that vision resonates with you, join us!
If you’d like to get involved, we’d love to talk. Try out Spice.ai OSS, Spice.xyz, email us “hey,” get in touch on Discord, or reach out on Twitter.
Luke