AI needs AI-ready data

A significant challenge when developing an app powered by AI is providing the machine learning (ML) engine with data in a format that it can use to learn. To do that, you need to normalize the numerical data, one-hot encode categorical data, and decide what to do with incomplete data - among other things.
This data handling is often challenging! For example, to learn from Bitcoin price data, the prices are better if normalized to a range between -1 and 1. Being close to 0 is also a problem because of the lack of precision in floating-point representations (usually under 1e-5).
As a developer, if you are new to AI and machine learning, a great talk that explains the basics is Machine Learning Zero to Hero. Spice.ai makes the process of getting the data into an AI-ready format easy by doing it for you!
What is AI-ready data?
You write code with if statements and functions, but your machine only understands 1s and 0s. When you write code, you leverage tools, like a compiler, to translate that human-readable code into a machine-readable format.
Similarly, data for AI needs to be translated or "compiled" to be understood by the ML engine. You may have heard of tensors before; they are simply another word for a multi-dimensional array and they are the language of ML engines. All inputs to and all outputs from the engine are in tensors. You could use the following techniques when converting (or "compiling") source data to a tensor.
- Normalization/standardization of the numerical input data. Many of the inputs and outputs in machine learning are interpreted as probability distributions. Much of the math that powers machine learning, such as softmax, tanh, sigmoid, etc., is meant to work in the [-1, 1] range.
 Figure 1. Normalizing Bitcoin price data.
Figure 1. Normalizing Bitcoin price data.
- Conversion of categorical data into numerical data. For categorical data (i.e., colors such as "red," "blue," or "green"), you can achieve this through a technique called "One Hot Encoding." In one hot encoding, each possible value in the category appears as a column. The values in the column are assigned a binary value of 1 or 0 depending on whether the value exists or not.
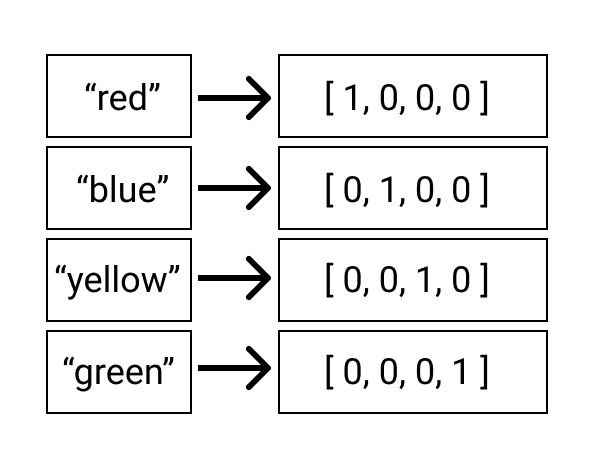 Figure 2. A visualization of one-hot encoding.
Figure 2. A visualization of one-hot encoding.
- Several advanced techniques exist for "compiling" this source data - this process is known in the AI world as "feature engineering." This article goes into more detail on feature engineering techniques if you are interested in learning more.
There are excellent tools like Pandas, Numpy, scipy, and others that make the process of data transformation easier. However, most of these tools are Python libraries and frameworks - which means having to learn Python if you don't know it already. Plus, when building intelligent apps (instead of just doing pure data analysis), this all needs to work on real-time data in production.
Building intelligent apps
The tools mentioned above are not designed for building real-time apps. They are often designed for analytics/data science.
In your app, you will need to do this data compilation in real-time - and you can't rely on a local script to help process your data. It becomes trickier if the team responsible for the initial training of the machine learning model is not the team responsible for deploying it out into production.
How data is loaded and processed in a static dataset is likely very different from how the data is loaded and processed in real-time as your app is live. The result often is two separate codebases that are maintained by different teams that are both responsible for doing the same thing! Ensuring that those codebases stay consistent and evolve together is another challenge to tackle.
Spice.ai helps developers build apps with real-time ML
Spice.ai handles the "compilation" of data for you.
You specify the data that your ML should learn from in a Spicepod. The Spice.ai runtime handles the logistics of gathering the data and compiling it into an AI-ready format.
It does this by using many techniques described earlier, such as normalization and one-hot encoding. And because we're continuing to evolve Spice.ai, our data compilation will only get better over time.
In addition, the design of the Spice.ai runtime naturally ensures that the data used for both the training and real-time cases are consistent. Spice.ai uses the same data-components and runtime logic to produce the data. And not only that, you can take this a step further and share your Spicepod with someone else, and they would be able to use the same AI-ready data for their applications.
Summary
Spice.ai handles the process of compiling your data into an AI-ready format in a way that is consistent both during the training and real-time stages of the ML engine. A Spicepod defines which data to get and where to get it. Sharing this Spicepod allows someone else to use the same AI-ready data format in their application.
Learn more and contribute
Building intelligent apps that leverage AI is still way too hard, even for advanced developers. Our mission is to make this as easy as creating a modern web page. If the vision resonates with you, join us!
Our Spice.ai Roadmap is public, and now that we have launched, the project and work are open for collaboration.
If you are interested in partnering, we'd love to talk. Try out Spice.ai, email us "hey," get in touch on Discord, or reach out on Twitter.
We are just getting started! 🚀
Phillip











 Figure 1. Time Series processing visualization: a time window is usually chosen to process part of the data stream
Figure 1. Time Series processing visualization: a time window is usually chosen to process part of the data stream Figure 2. AI training without interacting with the environment (real world nor simulation). Only gathered data is used for training.
Figure 2. AI training without interacting with the environment (real world nor simulation). Only gathered data is used for training.

